Arches Modeling Documentation
The following documentation presents information, compiled by the Arches Resource Model Working Group, on using and creating Arches Resource Models and Branches for use in Arches implementations. Each guide will help Arches users to understand the basic concepts behind modeling in Arches, the ARM WG methodology for Arches Resource Models, and the benefits of adopting the ARM WG methodology, as well as other resources for more information.
This documentation supplements the information on Resource Models in the official Arches documentation.
To access the Arches Package Library, click here.
This documentation is a WORK-IN-PROGRESS.
BASIC CONCEPTS
By clicking on the SLIDESHOW link, you will be able to access information on the following topics. You can also go to the topic section by clicking each topic below:
What is a Data Model?
Types of Data Models
Structured data
Key elements of structured data
Structured data in a data model
What is a Semantic Data Model?
Semantic Standards
Semantic Formats
Semantic Ontologies
Semantic Web
What is an Arches Resource Model?
Resource Model and Branches
Anatomy of an Arches Branch
Data Types
Concept Collections
Relationships between Resource Models
Arches Designer
Encoding the ontology
Reference Data Manager
The Modeling Process
Data requirements
Data content standards
Creating a conceptual model
Building Arches Resource Models
Introduction
The information in this section introduces some concepts that will be helpful to understand before engaging with the ARM WG methodology for Arches modeling.
Generally, the concepts have a direct relationship to the modeling process and why it’s important.
What is a Data Model?
A data model establishes the overall organization of data in any given database or system.
Data models can work on a conceptual level as well as a functional level. A conceptual data model provides the overall vision and framework for data organization but might not be adequately interpreted, structured and encoded for a particular software application. A data model that is also functional, such as an Arches Resource Model, is ready to be loaded into and expressed through a software application, in this case, Arches.
This documentation focuses on modeling functional data models, Arches Resource Models, that rely on conceptual frameworks.
Types of Data Models
In addition, there are different types of data models, often corresponding to the type of database or system. For example, a relational data model, which corresponds to relational databases, is based on a table structure. A graph data model, which often corresponds to graph databases, focuses on the data itself and the relationships between data. As a note, Arches Resource Models are graph data models.
Because Arches Resource Models are graph data models, it is important to understand structured data and how it forms the basis for graph data models.
Structured data
Structured data is data that is organized and formatted in a way that is machine-readable, or in other words, usable by computer applications for processing, analysis and other functions.
In relational databases, the structure of the data is created by tables. However, in order to increase portability, interoperability and longevity, data should be structured to be self-describing and independent of any particular software application.
To understand how structured data can achieve this, it is important to understand some key elements of structured data.
Key Elements to Structured Data
The following elements help to form the foundation for data that is meaningful and useful:
Structured data consists of clean and consistent data, with terminology that is defined by established controlled vocabularies. All database types can benefit from data that have these two elements.
Structured data also has elements that are essential in graph databases: the ability for each instance of data to be uniquely identified, preferably through a universal unique identifier, and the ability to create meaninful relationships between data instances through the use of triples.
Clean Data
Clean data is consistent in terminology, formatting, and structure through the entirety of the table or database.
For example: consistent date formatting i.e. 2019-10-02 instead of 10/2/19
preferred terminology i.e. United States of America instead of USA
Organizational standards help determine preferred format and structure
OpenRefine is a great, open source tool to help clean data
Controlled Vocabularies
Controlled Vocabularies are the set of standards chosen for preferred terminology used within a database.
They help create consistency when data can be incredibly messy, with misspellings, homonyms, and cultural/national differences.
Preferred vocabularies are established and stored in thesauri that should be shared for enhanced data interoperability.
Here is a primer to controlled vocabularies posted in the Implementation Considerations for the Arches Project.
Some examples:
The Getty Art and Architecture Thesaurus (AAT)
Library of Congress Subject Headings (LCSH)
The Arches Project manages its Controlled Vocabularies and Thesauri through the Reference Data Manager (RDM). For a more detailed guide on the RDM, click here.
Universal Unique Identifiers
Universal Unique identifiers (UUID) are associated with any given entity within a database structure. Each entity has a uniquely coded identifier that ensures exactly what it is. A UUID is a 128-bit number that differentiates the term from any other possibilities found online. This 128-bit number is difficult to replicate, as there are 3.4 x 10^38 possible alphanumeric combinations (an extremely large number!).
Arches utilizes UUIDs, e.g. 662b53c0-2e26-4b87-a6d0-109b7f611e05
Similarily, a UID (Unique Identifier) or URI (Uniform Resource Identifier) may be unique within an organization, but not necessarily unique universally. For example, a university student identification number is a UID that will not be repeated within the context of that university. A Social Security number also is a UID because it is specific to one single person within one single context and cannot be repeated.
A UID can also link an entity to a controlled vocabulary. The AAT record number can replace the name of any entity because it links back to the original preferred authority record. For example, the AAT record for ‘database’ is http://vocab.getty.edu/aat/300028543, with the UID being 300028543.
Usage of a UID or UUID is important within a database or spreadsheet in order to faciliate sorting and filtering information, as well has link back to specific entity within the database system.
What is a semantic data model?
When previously describing this triple:
a person (entity) is identified by (property) a name (entity)
both entities and the property are understandable to humans who understand English because they are written in a natural language. However, a computer only sees strings of letters, so both entities and the property must be given additional machine-readable meaning, so that a computer can parse and interpret the data.
A semantic data model is a graph data model for which each entity and property in the data model is associated and encoded with semantic metadata that describes what each entity and property refers to in a way that conforms to standard computer formats.
Further, to ensure that data can be more portable, interoperable, and reusable over the long term, it is essential that the conceptual framework for as well as the format of the semantic metadata be based on recognized standards.
Semantic Metadata Standards
There are two types of standards that interact when it comes to semantic metadata:
- Standards that define the data format (i.e. RDF/XML)
- Standards that define the conceptual data framework or ontology (i.e. CIDOC CRM)
Semantic Formats: RDF
RDF (Resource Description Framework): A classification schema to construct conceptual data models. The RDF is a set of standards specified by the World Wide Web Consortium (W3C).
The RDF is constructed by a series of expressions about a resource that are formatted in a semantic triple. This semantic triple is structured: subject-predicate-object
The RDF defines a model and a set of elements through a domain-specific syntax to encode information in a machine-readable format.
Semantic Ontologies
An ontology is a formal organization of a data structure or knowledge graph based on standards, establishing relationships between entities and their properties. An ontology is a way to structure semantic understanding shared by members of a specific domain.
In the cultural heritage domain, which is the main focus of the Arches Resource Model Working Group, there are prevalent existing ontologies, developed by domain experts, that are built and widely used for institutions to model and integrate their own data resources according to established structure and guidelines.
Examples:
- CIDOC-CRM – The ontology that Arches comes preloaded with.
- Linked.Art – The ontology, based primarily on the CIDOC-CRM, that the Arches Resource Model Working Group uses.
Links:
Semantic Web
The Semantic Web is the vision to make the world wide web machine-readable, such that all online data and resources are linked by a Unique Resource Identifier (URI). This will promote the navigation between resources and to improve automation for information retrieval online.
The goals of the Semantic Web are to:
- Structure meaningful content on web pages to promote machine automation in accessing and processing data
- Encode the semantics (meaning) of the data through designated frameworks (RDF and OWL)
- Promote Natural Language Processing and Semantic Search to support enhanced navigation and searchability on the web and from a variety of different sources.
Further reading:
What is an Arches Resource Model?
An Arches Resource Model is a semantic graph data model formatted for use with the Arches Platform. Arches Resource Models also include the information and formatting for the data entry interface (i.e. forms) to input the data and the report to display the data for each Resource Model.
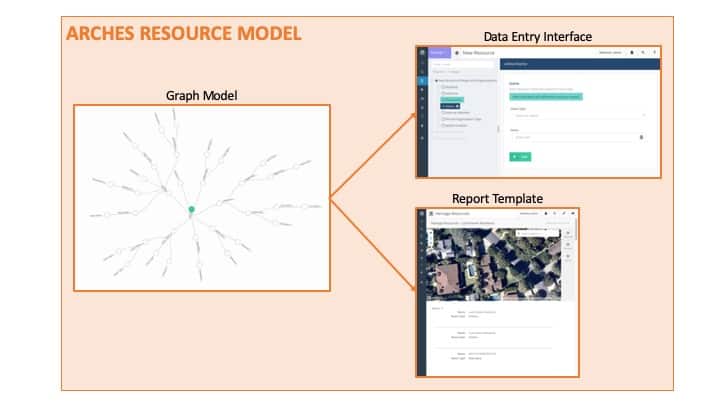
For example, if your Arches instance records information on Buildings, People, and Activities, you would typically create a Resource Model for Building, a Resource Model for People and a Resource Model for Activities. This would result in a data entry interface and report template for Buildings, a data entry interface and report template for People, and a data entry interface and report template for Activities.
All of this is encoded in a JSON file that can be exported from one Arches implementation and imported into another. In other words, the same Arches Resource Model or set of Arches Resource Models can be used by different Arches implementations.
The Arches Resource Model Working Group focuses primarily on creating guidance on the semantic graph model portion of the Arches Resource Model as well as providing sample Arches Resource Models, as well as Branches, that can be used and modified by various Arches implementers.
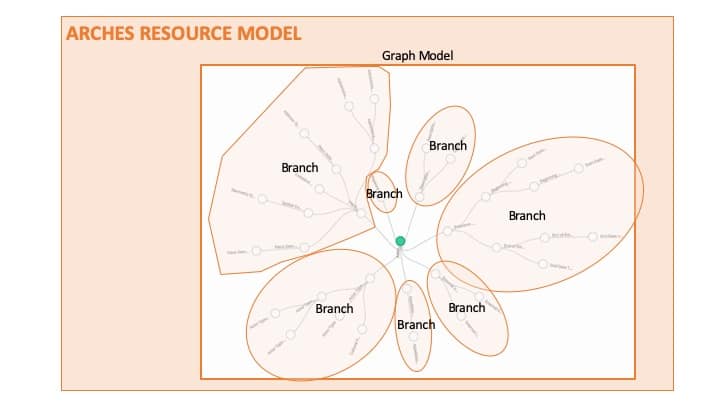
Resource Models and Branches
(Arches) Resource Models consist of discrete Branches that function as smaller graph models within the larger whole.
For example, a Resource Model for Person might be composed of a Name branch that contains all of the data related to a person’s name and a Description branch that contains all of the data relating to a descriptive statement about a person.
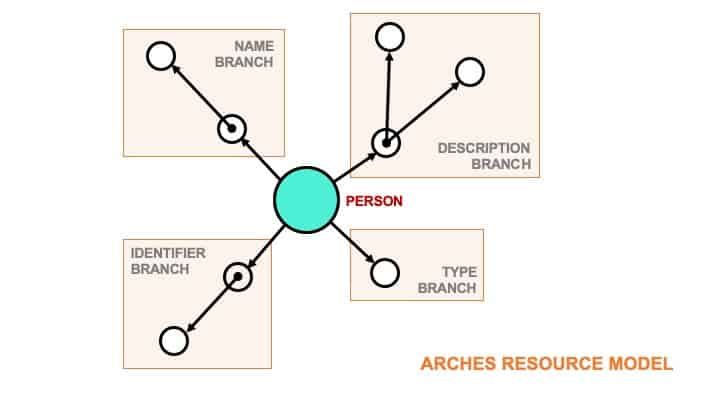
A Branch can be used by many different Resource Models. For example, basic Name and Description branches can be used by the respective Resource Models for People, Buildings, and Activities. And similar to Resource Models, Branch information is encoded in a JSON file that can be exported from one Arches implementation and imported into another.
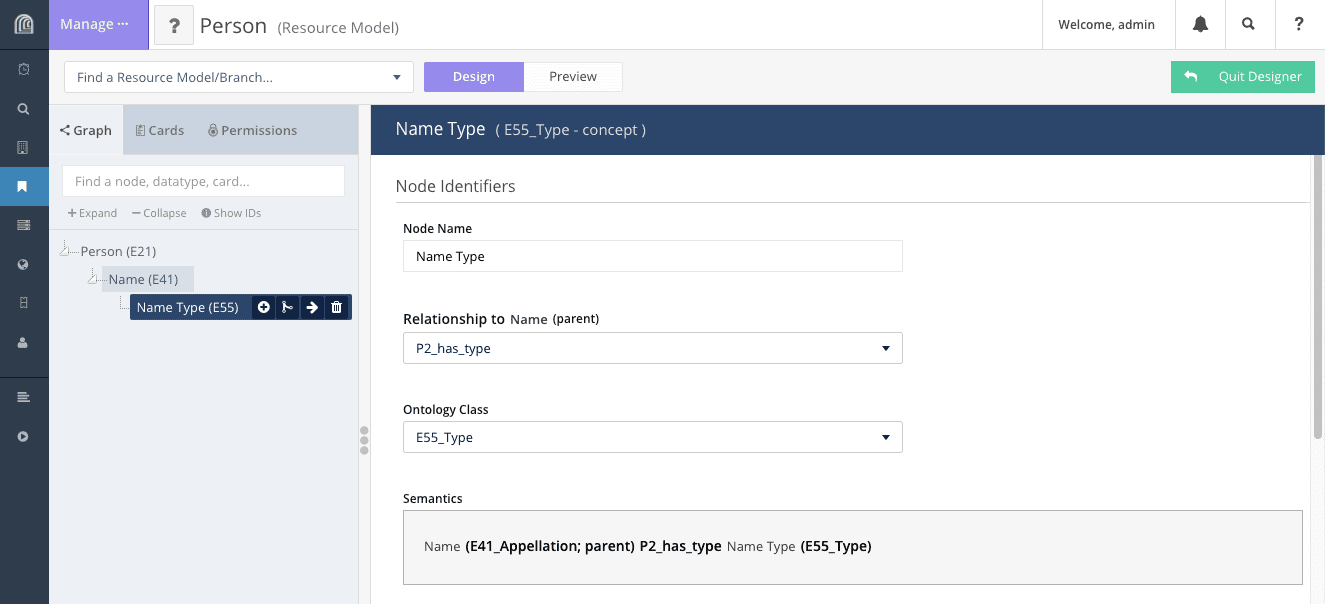
Anatomy of an Arches Branch
An Arches Branch typically groups data together that is thematically related. In the example below, this simplified Name Branch consists of the triple formed by “Name”(entity) “has type”(property) “Name Type”(entity).
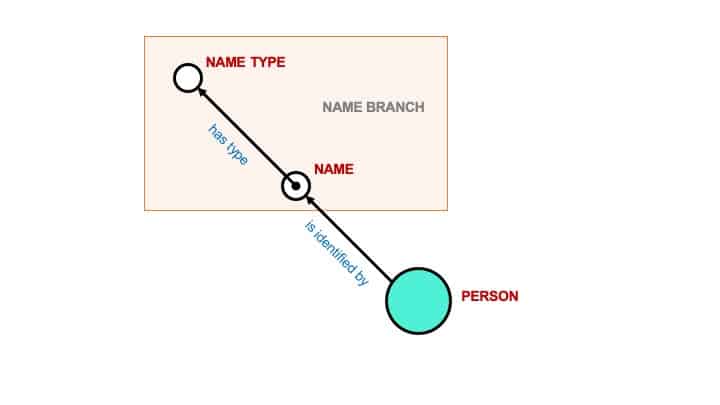
In Arches, the entities are represented by Nodes and the properties are the Relationships. “Name” and “Name Type” are Nodes and “has type” is the Relationship between the Nodes.
In using the CIDOC CRM ontology, each Node is assigned a CRM Class and each Relationship is assigned a CRM Property. The semantic statement formed by the branch then reads as: “Name” (as defined by CRM Class E41 Appellation) “has type” (as defined by CRM Property P2 Has Type) “Name Type” (as defined by CRM Class E55 Type).
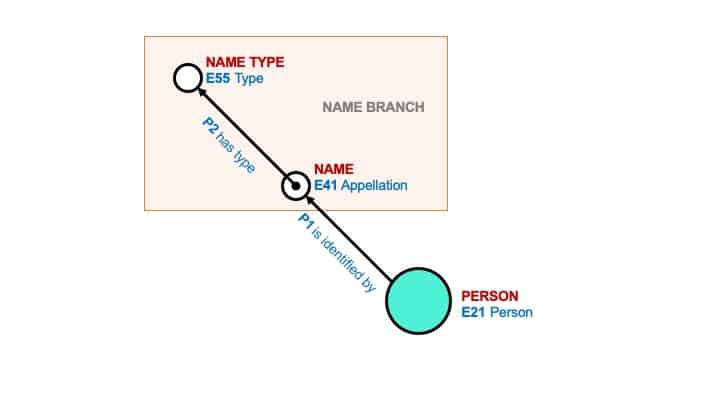
This defines the structure for a very simplified version of a Name branch. It is possible that more types of information would need to be represented in a Name branch, such as the language of Name or the source of a Name, and additional Nodes and Relationships can be added to accommodate such needs. It is important to note that Arches can easily be configured to record as many instances (entries) of the data represented in the Name branch as needed.
For example, below are two instances of the Name branch for the same Person.
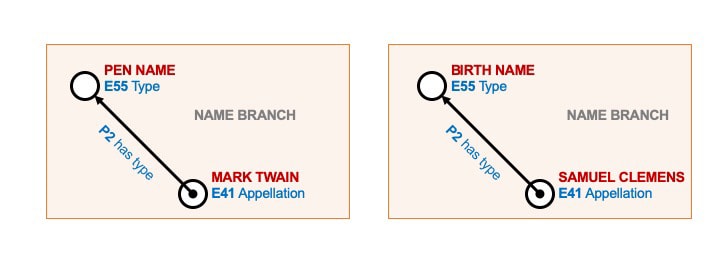
Mark Twain, the author of “The Adventures of Tom Sawyer”, was given the name “Samuel Clemens” at birth, and above is an example of how the Name branch structure shown is able to represent both names along with the type of name associated with each.
Data Types
Each Node in a Branch/Resource Model is assigned a data type that defines what kind of data can be entered for that Node and how data is entered. Here is a listing of some of the data types that can be assigned to a Node in Arches:
- Semantic – Nodes with a semantic data type carry no data, but serve to enforce the semantic structure and grouping of nodes.
- String – This data type supports the entry of alphanumeric text.
- Number – This data type supports entry of numbers.
- Date – This data type supports the entry of date and time.
- Geojson Feature Collection – This data type supports the entry of geospatial data.
- File – This data type supports the upload of various file types and how they are visualized.
- Resource-Instance – This data type supports the connection of Resource Models to each other via a specific Node.
- Concept – This data type supports the selection of data from a controlled vocabulary managed by the Arches Reference Data Manager.
- Domain – This data type supports the selection of data from a list that is not managed by the Arches Reference Data Manager.
- IIIF Annotation – This data type supports the import and annotation of images served by a IIIF image server.
- Extended Date Time Format – This data type supports of the input of date information according to the Library of Congress’ Extended Data Time Format.
Concept Collections
The Concept data type connects a Node to a controlled vocabulary for data entry. In Arches, controlled vocabularies are called Concept Collections. In the Name branch example below, the node for Name Type would be assigned the Concept data type which would also necessitate the designation of a Concept Collection that contains the Concepts (or terms) for Name Type.
The Concept Collection would include the Concepts of “Birth Name” and “Pen Name”, as well as other types of names. Concepts and Concept Collections are managed by Arches in the Reference Data Manager.
As described in the section on Controlled Vocabularies, Concepts and Concept Collections have their own organizing principles and are an extension of the data model structure.
Relationships between Resource Models
Through the resource-instance data type, relationships can be created between Resource Models.
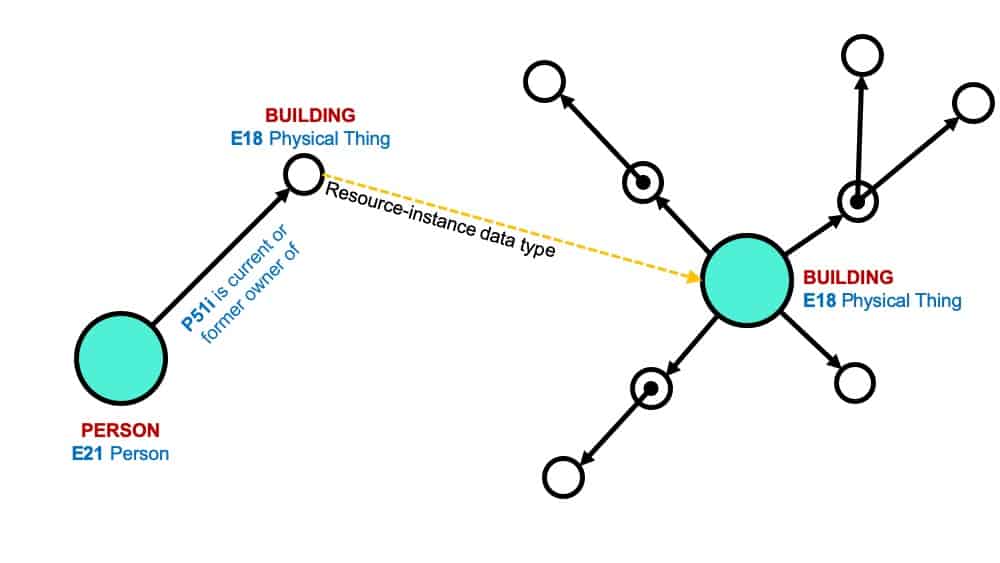
In the example above, the Person Resource Model has a Node for Building that the Person currently or formerly owned. This Node was assigned a resource-instance data type and links to the Resource Model for Building. This allows instances of the Building Resource Model to be associated with many different instances of the Person Resource Model and other Resource Models.
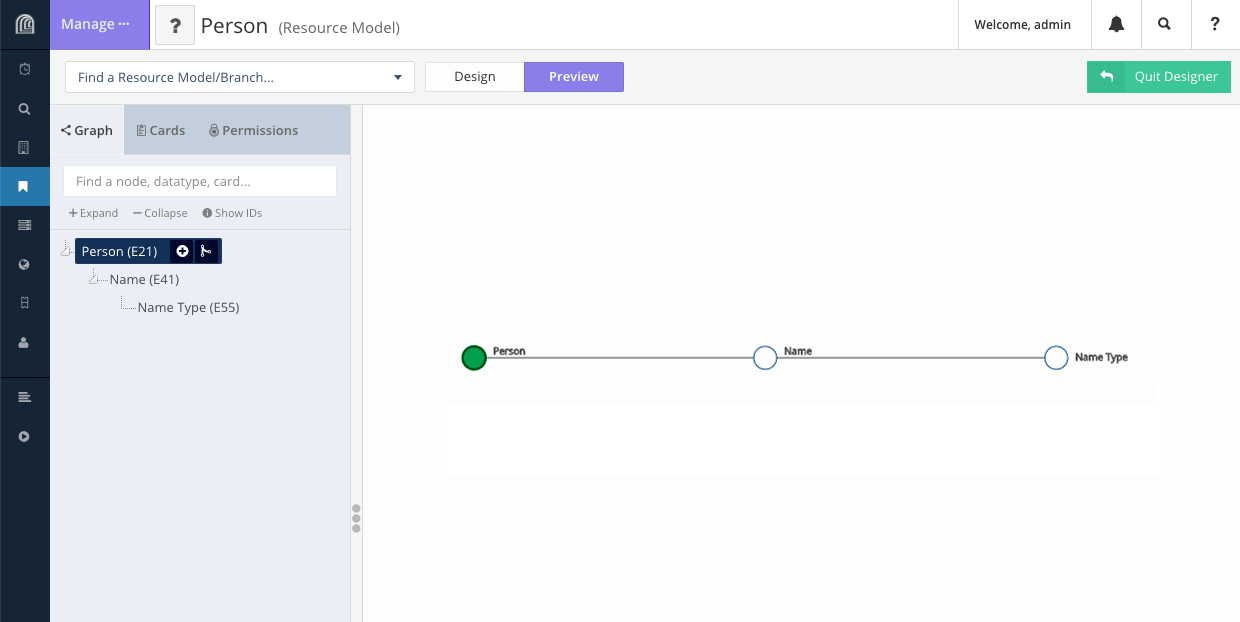
Arches Designer
Arches Designer is a tool that gives Arches administrators the ability to create Resource Models and in doing so, dynamically generate the Arches user interface and design the underlying data structure with no coding experience necessary.
Further reading:
Encoding the ontology
Most Arches packages use an ontology that is CIDOC CRM-based, and as a result, the Arches Designer generally has the classes and properties of the CIDOC CRM preloaded and restricts the selection of inappropriate class and property combinations.
Reference Data Manager
The Reference Data Manager is the Arches interface that gives Arches administrators the ability to manage the controlled vocabularies that power both concept search and data entry.
The RDM manages controlled vocabularies through broader thesaurus concepts.
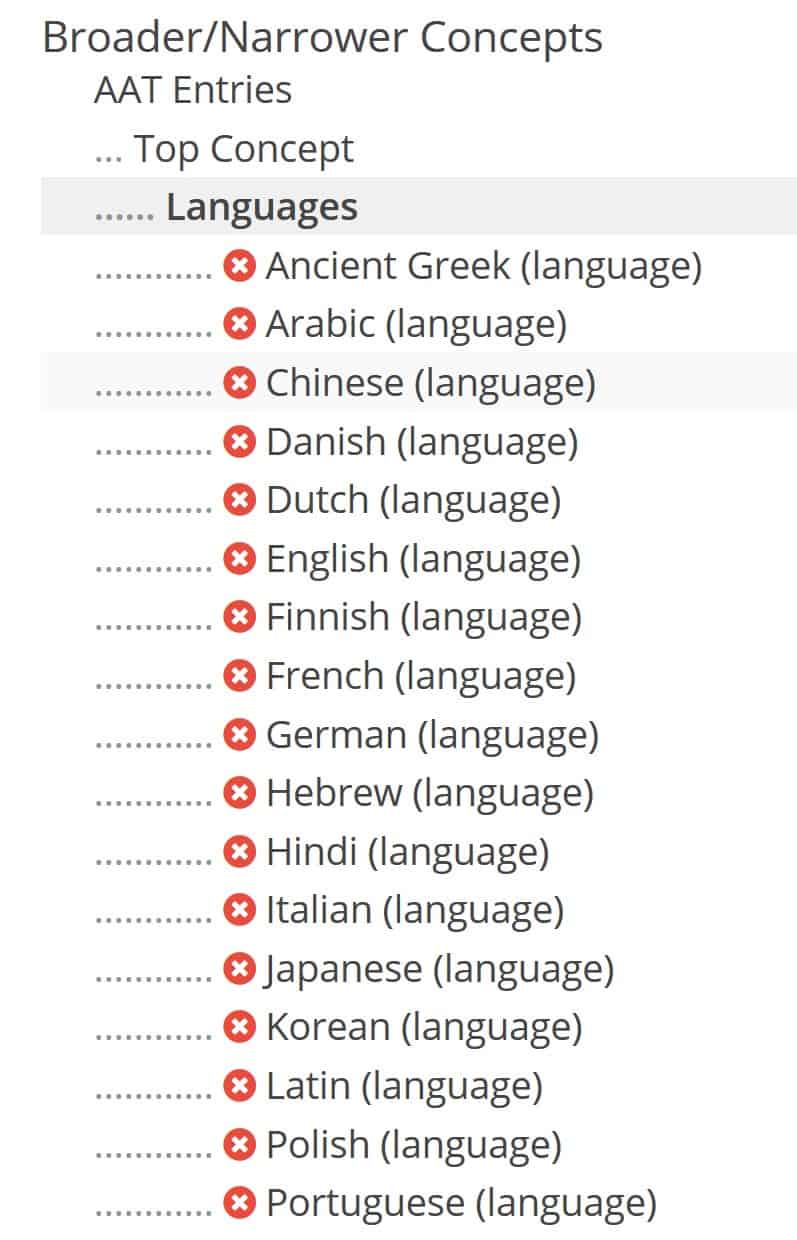

Easily import authoritative thesauri, such as from the Getty Art and Architecture Thesaurus (AAT).
The Modeling Process
To create one or more data models from scratch, generally one should start by having a clear idea of what the overall purpose and goals are of the system that the data models will reside in. This is particularly important with Arches, since the Resource Models determine all interactions with the data, so not only the data organization but also the data entry and discovery.
Once the overall system requirements are defined, then the modeling process can begin by assembling the data requirements.
Data requirements
When gathering data requirements, here are some helpful questions to ask:
- Are there existing data that need to be incorporated in the system? In other words, are there any legacy data?
- Are there existing data standards that I have to comply with? Or will the system’s data be interacting in some way with data housed in other systems?
Once you know what data you want to manage in your system and how it will or will not be interacting with data in other systems, you can start to create a conceptual model that encompasses all of your data.
Data content standards
A data content standard defines the essential items of information that should form a dataset, specific to a use case.
An example of a data content standard is MIDAS Heritage. In addition to suggesting “the minimum level of information needed for recording heritage assets” in the United Kingdom, the MIDAS Heritage data standard also “covers the procedures involved in understanding, protecting and managing these assets.”
CIDOC is now finalizing an international standard for the inventory of archaeological and architectural heritage known as the International Core Data Standard for Archaeological and Architectural Heritage, through the input of the ICOMOS International Documentation Committee (CIPA). It is based on the earlier Core Data Index to Historic Buildings and Monuments of the Architectural Heritage adopted by the Council of Europe in 1992, and the Core Data Standard for Archaeological Sites and Monuments, which resulted from collaboration between CIDOC and the Council of Europe and was adopted in 1995.
An example of a data standard for metadata, regardless of domain, is the Dublic Core Metadata Initiative.
Further reading:
Creating a conceptual model
A conceptual model organizes all of the data in a system in order to make the relationships between data as explicit as possible.
Examples of creating simple conceptual models are forthcoming.
Building Arches Resource Models
And once you have a good conceptual framework for how you want your data to behave in Arches, here some brief guidance on how to translate that into Arches Resource Models. This would be the basic creation of Arches Resource Models. We will go into the Arches Resource Model Working Group suggested modeling patterns in the next section.
METHODOLOGY (coming soon!)
Click here for SLIDESHOW (Coming soon!)
Click here for PDF (Coming soon!)
(Coming soon!) Documentation on the following topics:
Introduction
Assumptions
ARM WG Ontology
Linked Open Data
What makes a good data model?
Modeling Patterns
BENEFITS
Introduction
The benefits of modeling your data in Arches using the principles described in this documentation, include the following:
Domain expertise
The CIDOC-CRM has been developed by cultural heritage domain experts for those working in the cultural heritage field. The CRM provides the framework to build conceptual models for archives, libraries, and museums. Working with the CRM will allow cultural heritage institutions to partner with other similar communities and to build information systems that support specialized research questions
More information about the CRM can be found here.
Information Search and Retrieval
Structuring your data into a data model, or schema, will enhance the searchability and findability of information stored within it. The schema provides the outline for where and how the information is stored. The more detailed and precise your data models are, built using the Arches Designer, the better return of search results for those using your Arches instance. Linked Data is a graph structure that can enhance searchability by establishing semantic connections between resource elements.
Shareability and Interoperability
Linked Data and semantic standardization allow the possibility for organizations to share their data with other institutions who structure their data following the same guidelines. The benefit of sharing data in this way is to enhance collaboration between organizations and to share resources and work between multiple entities.
Structured data sets will enhance interoperability and data usability for a wider variety of computer and software systems.
GLOSSARY
General Data Management Terms
- Structured data: data that is organized and formatted within a database or other such repository to enhance data searchability and to allow for more effective processing and analysis.
- Data cleaning: the process of ensuring consistency and accuracy of records stored within a table or database, such as spelling, date order, or consistent identification.
- Standards: the rules or documented agreement on the format, structure, representation, usage, etc of the ways in which data are described or recorded. They are the best practices of how data and metadata should be described, formatted, or included in a data set.
- Controlled vocabulary: a set of standardized terms, thesauri, or subject headings that are preferred for a data set. It ensures consistency of vocabulary to control for spelling differences, homonyms, or name variations for a single defined entity.
- Data Model: An abstract, visual representation of data objects for a group or organization in order to structure a database. A good data model follows formalized standards, or best practices, in format and structure.
- Conceptual Model: A type of data model that establishes entities, their properties, and the relationship between each entity. The model is used to formalize entity relationships to represent the semantics of an organization.
- Ontology: An ontology defines the elements — entities and their properties — within a data structure. It formalizes the conceptual data model with a common controlled vocabulary, identifiers, and structure that allows for system interoperability of the database.
- Universal Unique Identifier (UUID): a 128-bit number used to reliably identify an object or entity within a database.
Arches Specific Terms
For a larger collection of Arches Terminology, see the Arches Glossary Here.
- Arches Designer: A user interface for facilitating database design, i.e. the creation of Resource Models. The Arches Designer consists of many different tools, such as the Graph Designer and Card Manager, each of which helps build a different facet of Resource Model creation.
- Reference Data Manager: The Reference Data Manager (RDM) is a core Arches module to create and maintain concept schemes (controlled vocabularies) or thesauri. It enables the creation and maintenance of controlled vocabularies for use in dropdowns and controlled fields within the various Arches Resource forms. For more information: [Reference Data Manager (RDM)](https://arches.readthedocs.io/en/stable/rdm/)
- ARM WG: The group established to provide consensus-based guidance on Arches Resource Models and constituent Branches, specifically on how to build and apply them. More information on the ARM [can be found here](https://www.archesproject.org/arm-wg/).
ADDITIONAL LINKS
Arches
CIDOC CRM
- CIDOC-CRM Primer
- CIDOC-CRM Tutorial
- CIDOC-CRM Video Overview with Stephen Stead
- Learning Ontology & CIDOC CRM
- CIDOC-CRM Functional Units
Other Examples
Contribution
We invite contributions to the ARM WG Documentation from any of our Arches Community Members. The documentation provided is a work-in-progress and would benefit from the experience of those who also developing resource graphs for their own implementations. We hope to expand this documentation for the variety of use cases of an Arches implementation.
Connect with us at our GitHub Repository or email us at contact@archesproject.org.
Last updated: January 2021